|
|
Implementation Details
We used our semi-automatic Web process acquisition method to collect descriptions of actual Web processes. In the current status of the acquisition, processes with interesting behavior patterns cannot be acquired completely automatically. So, for the purpose of testing the presented verification method we decided to synthesize process descriptions additionally. Using given domain ontologies (that would have been created by the acquisition method), the generated semantic descriptions of processes have non-functional properties and a behavioral description with input, output activities and local processes. We implemented a Java API to model process description and another API to model the request. The verification module then receives process description and request objects together with the used domain ontologies described in OWL2. HermiT (Hermit OWL Reasoner http://hermit-reasoner.com) is used to provide reasoning support during the verification of Web process descriptions.
The generated process descriptions vary in their complexity with up to 4 NFPs, up to 10 process steps (each of which with up to 3 arguments). We hand-crafted a description of a classification with 20 classes and classified each process in up to 4 of them. We performed tests with 3 queries:
(Q1) A proposition about process arguments and their properties,
(Q2) a conjunction of eventually consumed inputs and eventually returned outputs, and
(Q3) always have the ability to logout after a user has provided login credential. We omitted the NFRs due to space constraints.
For each request the verifier checks for each available process description if the request is a model of the description. This is done for each property that is constrained in the request. If classes of the classification hierarchy are used, the set of processes are simply retrieved from the classification hierarchy that is cached in the verification module and thus allows us to speed up the verification process. In an experiment we observed the time to retrieve all processes for which the request is model for their descriptions. These experiments where repeated for a various numbers of available Web process descriptions.
The results reveal the crucial need for the reduction of the search space as we did with the classification. Unsurprisingly, the use of expressive formalism lead to high computational effort, which is quickly increasing with increasing number of formal process descriptions. We also observed that the different complexity has a high influence on the query time. This observation justifies the use of a classification because the usage of classes reduces the query complexity by replacing model checking tasks with retrieval of off-line classified processes. Comparing the results of individual queries with or without classes reveals the substantial impact of the hierarchy on the verification performance. The shown experiments serve as a proof of concept as the purpose of this work is not the performance and scalability of the approach. Nevertheless, in order to achieve more usable results, we are currently experimenting with parallelizing the task of verifying queries against independent process descriptions and materializing the classification in a database (instead of a 20MB OWL Ontology for 40k process descriptions).
The implementation is available in the maven repository. To gain access to the maven repository, we send you a user login upon request to junghans(at)kit.edu .
The components to use can be included by adding the following dependency
<dependency>
<groupId>edu.kit.aifb.suprime.reasoning</groupId>
<artifactId>suprime-process-reasoning</artifactId>
<version>1.0</version>
</dependency>
Specification of a Request for Solution Templates
The user retrieves a ranked list of solution templates by specifying the request comprising available inputs, expected outputs, constraints on the data within the solution template and preferences on data provided by the Web processes that are part of the template. The following figure exemplifies such an request for the travel booking scenario.

A set of solution templates is created according to the algorithm presented in the paper. Each template may involves several Web processes available in the Web process repository. The list of solution templates is presented to the user that may inspects them in the process editor and adds them to the user’s favorites list.
The process editor reveals the process model of a solution template. The synthesized controlling process with inverse interaction behavior is also part of the template. The controlling process also involves process filters which either enable the compliance of Web processes to the specified constraints or support the computation of the ranking of the solution template outputs.
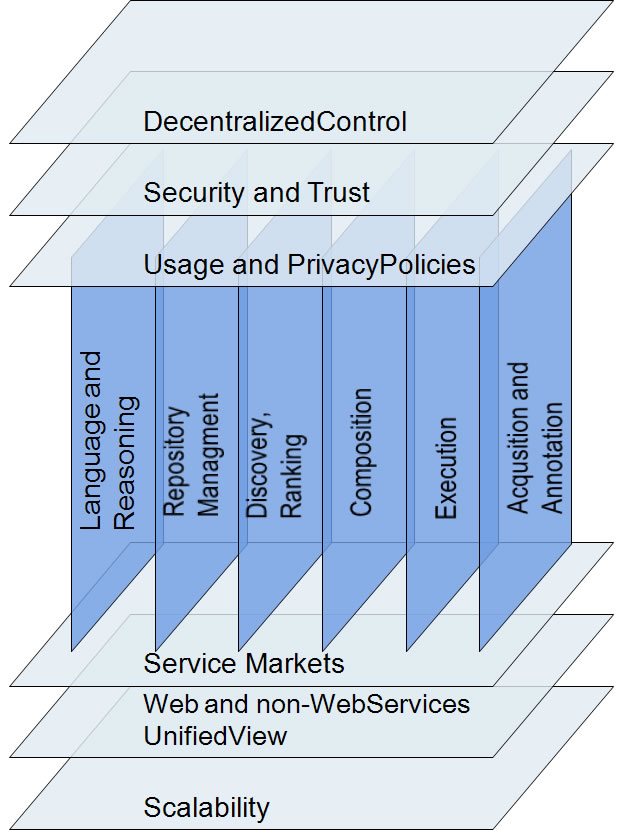
Our research within the field of Semantic Services is centered around the theme of the intelligent management and usage of Processes and Services. We are currently working on different research topics,which are illustrated in the figure below.
We classify the topics in two groups being orthogonal to each-other. The vertical topics represent areas where we conduct research work to deal with concrete challenges and offer solution to the actual problems.
Whereas, the topics with the horizontal orientation provide a broad, horizontal coverage of the conducted research, serving also as motivational problems.
The following Research Topics are addressed in our suprime Framework:
Discovery
The discovery of semantic Web service and process descriptions aims at identifying those descriptions, which satisfy the needs of a query. Our scalable discovery solution features high precision and recall of the discovered descriptions matching the query. We also plan to integrate the ranking phase into the discovery phase such that most valuable service descriptions are considered first for expensive matchmaking operations. more…
Ranking
The ranking component determines an ordering of the discovered service and process descriptions and considers user preferences on functional and non-functional properties. It enables automation of service related task (e.g., composition) by finding the most appropriate service or process for a given query. Therefore, the development of the ranking component comprises formalisms to specify preferences on properties and a scalable fuzzy logics based ranking algorithm. more…
Composition
Composition is an important mean for creating new services based on already existing ones. Therefore services are aggregated to form a new workflow, whose input and output parameters match those of the service requested by the user. In between those services, which compose the new workflow, there have to be matches between their parameters, i.e. preceeding services have to create those output parameters that are required by the following services. Not only is it important to find matching in- and output parametertypes but also such parameters that fulfill the purpose the user needs. Therefore, besides a technically matching, semantics have to be regarded considering the parameters and their use in the services. more…
Usage and Privacy Policies
Momentarily WS-Policy is used to regulate technical aspects of services with assertions defined by WS-* standards (e.g. encrypted communication). Our goal is to provide policies with formal semantics that regulate service behaviour.
In terms of Usage and Privacy Policies we are working towards the formal expression of usage policies, in order to automatically check permitted actions and required obligations for service executions.
Acquisition of Service Description
Provide automated methods to infer a formal model of the process behavior. Another goal is the semi-automated acquisition of processes in deep Web.
Processes can be edited and annotated in a visual manner by the process editor. Automatically acquired processes from the Web can be rectified and extended. Semantic descriptions are added to the descriptions of services and processes and are stored in the repository. more…
Language and Reasoning
In order to enable automatic method and tools, languages with formal semantics for describing services and processes as well for specifying constraints over services and processes are needed. Service and process description language should allow modeling of involved resources, competencies and credentials (non functional properties) and behavior (orchestration and choregraphy) including access control semantically and in a unified way. The language for specifying constraints on services and processes, e.g. for searching, ranking and composing the services and processes automatically, should allow specification of desired functionality (desired behavior and desired changes in the resources) and desired quality (e.g. preferences over the non functional properties).
Service Market Platforms and Negotiation
In contrast to the current situation where passive Web services are offered, our goal is to provide solutions for the autonomous and active engagement of services in economic activities. We intend to model the „intelligent” behavior of services, through Analytics methods for seamless monitoring and analysis of all relevant service activities.
Efficient discovery of services is a central task in the field of Service Oriented Architectures (SOA). Service discovery techniques enable users, e.g., end users and developers of a service-oriented system, to find appropriate services for their needs by matching user’s goals against available descriptions of services. The more formal the service descriptions are, the more automation of discovery can be achieved while still ensuring comprehensibility of a discovery technique.
Currently, only invocation related information of Web services is described with the W3C standard WSDL while the functionality of a service, i.e., what a service actually does, is described in form of natural language documents. In suprime, we use the pi-calculus based service and process description formalism. However, there are still a lot of Web services that are not annotated formally.
We have developed discovery techniques in order to provide users, e.g., end users, developers, and annotators, with a discovery component that is capable to consider semantic descriptions of Web services. Traditional non-semantic descriptions are not used for a full text based discovery, which makes use of the Web service descriptions provided by the WSDL service description files, the Web pages describing REST-ful Web services, and related documents found by a crawler.
The semantic discovery mechanism considers functionalities of services formally described with pre-conditions and effects. This discovery component enables users to enter a more structured goal (service classification, pre-conditions, and effects), then finds the available descriptions from the repository that match the goal by using the reasoning facilities. While keyword based search mechanisms may scale well, reasoning over logical expressions is computationally expensive. We therefore also develop an approach that on one side considers the functionalities of Web services, on the other side has the potential of scaling to a large number of Web service descriptions.
The ranking component determines an ordering of the discovered service and process descriptions and considers user preferences on functional and non-functional properties. It enables automation of service related task (e.g., composition) by finding the most appropriate service or process for a given query. Therefore, the development of the ranking component comprises formalisms to specify preferences on properties and a scalable fuzzy logics based ranking algorithm.
Composition is an important mean for creating new services based on already existing ones. Therefore services are aggregated to form a new workflow, whose input and output parameters match those of the service requested by the user. In between those services, which compose the new workflow, there have to be matches between their parameters, i.e. preceeding services have to create those output parameters that are required by the following services. Not only is it important to find matching in- and output parametertypes but also such parameters that fulfill the purpose the user needs. Therefore, besides a technically matching, semantics have to be regarded considering the parameters and their use in the services. Matching between parameter-notations that use different vocabularies but share a semantic meaning should be found and matched, so that the specific services can be composed nonetheless. The aim is to provide methods that ensure that a composition is syntactically as well as semantically correct.
While this has to be an automatic proceeding, due to the huge amount of possible workflow compositions, there may be manual parts for the human user, which ensure transparency and control. Non-functional properties are maybe not covered satisfactory, even if a sufficient service description language is provided. This may happen because the user himself has problems in articulating or valuating his non-functional preferences. A manual revision of the composition should ensure that all his needs and specific wishes are regarded. Therefore we strive for a semi-automatic composition.
Furthermore, a dynamic reconfiguration at runtime should be possible if required. This can be the case if some services that are used in the composition fail or are overloaded or because some external or internal parameters changed. The system should recognize such cases and react in that way, that it autonomously finds solutions and provides them, e.g. by replacing a part of the composition.
We regard uniform data mediation as an important basis for our composition methods. Thus, the service description language has to ensure these among other things. The compositions trustworthiness should be compatible for SOC, so that its unlimited usage can be guaranteed.
The scope of this part of our research is the Semi-automated mining of processes and describe them semantically. Mining processes from data repositories offers to the organizations the solution of obtaining with more efficiency and effectiveness relevant knowledge about their running business processes and services. These processes are often complex, as well as difficult to understand and model manually. Being able to automatically discover the processes and obtain models that formally describe them, allows us to detect possible problems or bottlenecks in our systems, and make further optimizations. Another advantage of obtaining such process models is that we are able to apply composition among different processes exposed as services, and make them executable.
Semantic Process Mining
The set of data to be analyzed and mined for services and process descriptions may be available as a source in various formats, such as in relational databases, websites, WSDL files, or other semi-structured files. Each source is read separately serving as input for the Automated Learning module.

The Automated Learning is a central component in the scope of this research work, since it will be responsible for mining the data source and generating appropriate ontologies and process annotations. Process descriptions and ontologies are then registered in the Process Base, using the Repository Management System.
These descriptions of processes and services may be later searched and displayed in a graphical interface, through which the user is also able to modify the process model. Using the graphical tools, the user may correct parts of the generated process model or add further annotations, to make the derived model more accurate and complete.
Process Mining Methodology

For each type of dataset, we make a selection of the metadata and data analysed as the most appropriate for including process descriptions. These are addressed as target data. They will be further preprocessed to reduce noises and tidy up data, and then transformed possibly into an event-based format where we will deploy process learning mechanisms.
The transformed data will include information about the services of which the process is composed, roles of people that have conducted the activities, artifacts generated during the process, and relationships between these elements.
The final output of mining the transformed dataset will be the formal description of the process that we store in our Process Base. In the graphical editor, this process will be displayed in a formal graph representation based on its formal description. Though the editor it can also be modified and refined.
Mining Semantic Descriptions of Processes on the Web: a semi-automatic Approach
Link to the Suprime Process Description Editor
Repository of Ontologies and Process Descriptions
The process descriptions and ontology models of our repository are displayed in the main page, central section of the editor. A table view as illustrated in the figure below may represent a more comprehensive form of the repository.

Create a new Suprime Process Model
A new suprime process model may be created and enriched with elements found in the Shape Repository panel, as displayed in the following figure:

Create a new Suprime Ontology Model
A new suprime ontology model, containing Concepts and Instances, as well as relationships among them, may be created as displayed in the figure below:

|
News March 14, 2010
Presentation of Bachelor Thesis "Development of suprime Tool for Process Annotation" The student Benjamin Fischer presented his Bachelor Thesis, which he successfully developed by our group. The thesis consisted in the development of a Suprime Tool for the semantic annotation of processes, via the extension of oryx editor. His presentation may be found
under this link.
January 18, 2010
Lecture Series "Trends in e-Commerce" Prof. Rudi Studer held a lecture entitled "Innovative Methods for �Service Engineering and Management" in the Lecture Series "Trends in e-Commerce" organized by Vienna University of Technology, Austria. On this link you may find the slides of this lecture.
December 2,2009
SOA4All Technical Project Meeting
A technical project meeting of the SOA4All project was held in Vienna, Austria, from November 30 to December 1. The meeting addressed the scientific achievements and outcomes of the work packages. Action points were defined and success criteria and impact indicators for the project were discussed as the project will finish in less than 16 months.
November 16, 2009 InterLogGrid Project Meeting
Second project meeting of InterLogGrid project took place on November 16 and 17 in the Hohenheim University, Stuttgart. Among other topics, interesting discussions were made about the possible scenarios and use cases of Logistics Services on a Semantic Grid. Next meeting will take place in Berlin, on the January 18 2010.
|